How we use Pivotal Tracker at OmbuLabs

We like to use GitHub to its full potential at OmbuLabs , so any tool we add to the toolset needs to integrate nicely with it. As a growing agency working in larger and increasingly more complex projects, we need a project management tool that allows us to keep track of our work and plan accordingly. For this, we use Pivotal Tracker .
There are many things that are easier with Pivotal Tracker, as long as you are using it the right way. Some of its features are very useful for agile teams like ours. This is how we like to use it to ship value with every sprint and keep track of our team velocity .
Step 1: Writing user stories
All tasks related to a project should be tracked through user stories. A good way to think about user stories is that it is a high-level requirement card. A user story can be used to represent a technical requirement, a use case, a usage requirement or even chores the development team needs to complete. Pivotal Tracker gives you the ability to create 4 different types of stories:
- Feature
- Bug
- Chore
- Release
Most stories will be either features or bugs, although sometimes there will be chores to be done. If a chore reoccurs many times, then it’s probably time to write a feature to reduce the time spent completing that chore.
Both project stakeholders and the Scrum team can request stories. If a developer sees a need for a story, they should create it. If the product owner needs to define a feature that should be added, they should create a story. However, new stories will always be added to the Icebox. Once the sprint is planned, stories being worked on will be dragged into the current iteration section of the project.
In order to indicate priority, we organize the Icebox from most important to least important stories, from top to bottom. This way, everyone involved in the project has a clear picture of the priorities.
Step 2: Describing user stories
Every user story should be a representation of a requirement and consist of a summary and a description.
The summary is a concise description of the requirement and it clearly states what needs to be done and why. For a user story representing a use case, for example, you should follow this structure:
As a < type of user >, I want < some goal > so that < some business goal >.
The description of the user story should describe the expected outcome clearly, so that both project stakeholders and the development team understand exactly what needs to be done. The description should also contain the acceptance criteria for the story and the definition of done (when is the story considered finished).
Step 3: Estimating user stories
We like to start our sprints on Mondays and end on Fridays. Depending on the project, sprints may be 1 or 2 weeks long.
When we plan the sprint on Monday, we define which stories will be worked on during the sprint. At that point, stories should also be estimated. We like to use the Fibonacci sequence to estimate stories and we use an internal tool to do blind estimation as we are a remote, distributed team.
It is also important to keep in mind that when estimating stories, we are estimating complexity , not hours. Different developers might take different amount of time in completing that story, so we shouldn’t estimate hours.
Story points are not hours. Given a user story that has 3 story points of complexity, a Senior Developer might take 2 hours shipping it, a Junior Developer might take 5 hours shipping it.
This will affect metrics such as team velocity, which are important when planning sprints. So it is always important to remember to think in terms of story points, not hours.
Once stories are estimated, the team is ready to kick-off the sprint.
Step 4: Starting user stories
Once the sprint is planned, it’s time to start working on the stories currently in the iteration.
To track the different stages of a story, Pivotal Tracker gives you four different states for a story:
- Started
- Finished
- Delivered
- Accepted / Rejected
When a story is started, the clock starts ticking on that story, and we should try to finish it as soon as possible. In Pivotal Tracker, to indicate work on a story has been started, the Start button should be clicked.
This indicates to the project team that the story is now in progress and a developer is actively working on it.
##Step 5: Finishing a story
When the time comes and you are done working on the code and tests for that story, you will submit a pull request and attach it to the user story using the Code field in Pivotal Tracker . At that point, you can click the Finish button.

After the story is finished, it should go through Code Review and QA before it can be accepted.
Step 5: Delivering a user story
When your pull request has been approved by a code reviewer, you or the reviewer can deploy the story to a staging environment. At this point, the story can be delivered so that the product owner / relevant stakeholder can test and approve or reject the implementation.
Before you click Deliver you should perform a quick smoke test to make sure that your changes were successfully deployed to the staging environment.
After that, you can go ahead and Deliver the user story. This will move the story to an Accept/Reject state:

Step 6: Accepting or rejecting a user story
If the Product Owner approves the story, the pull request can be merged and deployed to production by the submitter or the reviewer. The story is then accepted and no more work is necessary in this user story. Great!
If a story is rejected, a detailed description explaining the rejection will be provided. The Product Owner should ask themselves these questions to describe the problem/s:
- What did I expect and what did actually happen?
- What cases worked and what cases didn’t work as expected?
- Was the interface clear enough to understand what was going on?
- Did I test many cases and it failed with an edge case?
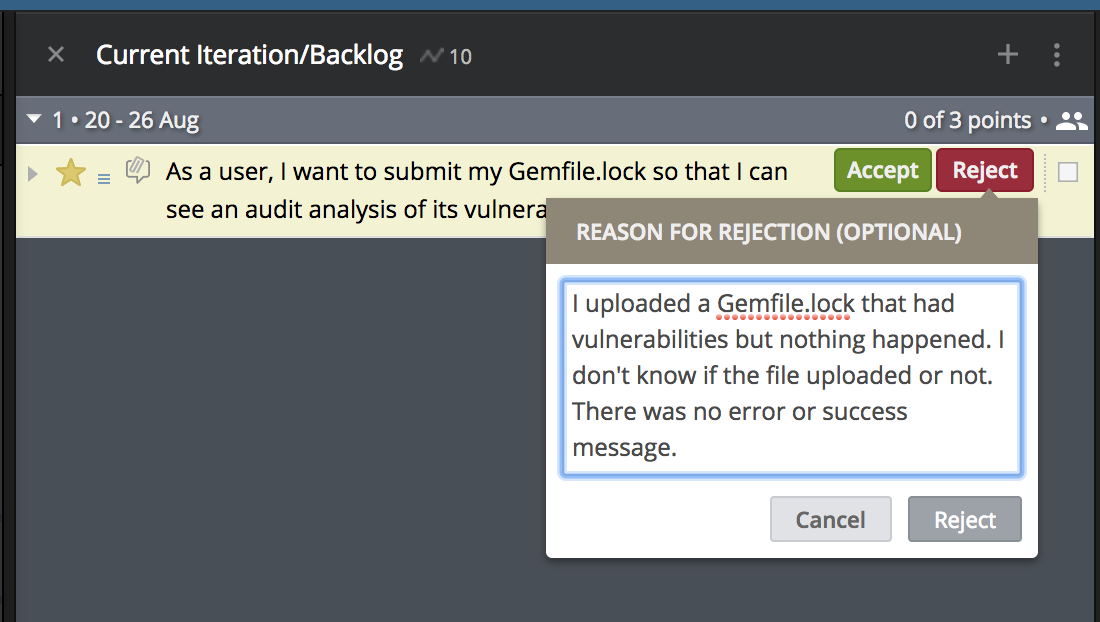
If possible, a description of the exact scenario and steps that were taken to find a problem with the user story should be provided. If adding a screenshot or a video would help, one should be added as a comment before the story is rejected.
Step 7: Restarting a rejected user story
There will be times when an implementation is not good enough. It may fall short in terms of usability, performance, or behavior. The good news is that our process works. Someone verified a feature you implemented and found issues with the implementation.
When the time comes, you will find a user story in this state:
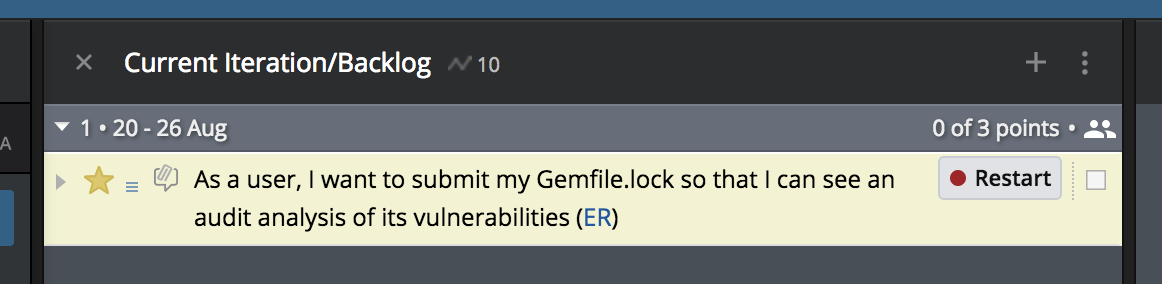
You can simply restart the user story and resume working on it. If you need to submit another pull request to patch the feature, you can continue with step 4.
What if there are issues after merging?
We should not be shipping bugs to production. However, if after the story has been accepted and deployed to production an issue is found, the story should not be changed to rejected.
At that point, a new user story should be created with the type set to bug and the issue found should be described. The team will then proceed to follow the process to fix the bug.
Conclusion
Pivotal Tracker provides a great way to track project progress and team velocity. This helps in determining when a big feature will be shipped. As much as we like to use GitHub for everything, Pivotal Tracker integrates nicely with them (they recently launched this integration!) which improves traceability from feature to implementation.
Additionally, Pivotal Tracker also integrates nicely with Slack , which we use to communicate with each other. This integration makes it easy to keep track of comments and notifications we need to address.
At OmbuLabs we like to work closely with our clients’ teams and communicate openly. We like how Pivotal Tracker makes it easy to communicate that some stories will be delivered in this sprint and some will have to wait until the next sprint. It is a great way to manage expectations. We like to invite our clients into our Pivotal Tracker project so we can work together in there; however, if our client already has a project management tool they use, we are happy to adapt.
We have also started using Pivotal Tracker for our internal projects more and more and we are seeing very positive results!