
Introduction
Have you ever wondered how does Medium recommend blogs to read or how does a platform with millions of users tells if a username is available or taken? If yes, you have come to the right place, as we are going to look at the data structure that makes this and a lot more happen. The data structure is Bloom Filter.
What are Bloom Filters?
Bloom Filters are data structures with unique properties of space-efficient and probabilistic nature. We will look at the 2 properties in detail later in the blog.
To understand Bloom Filters better, let’s read about the 2 concepts Bloom Filter depends on.
- Bit Array
- Hash Functions
Bit Array
It is an array data structure that stores only boolean values in it. It is used to map values of some domain with {0, 1} in the bit array.
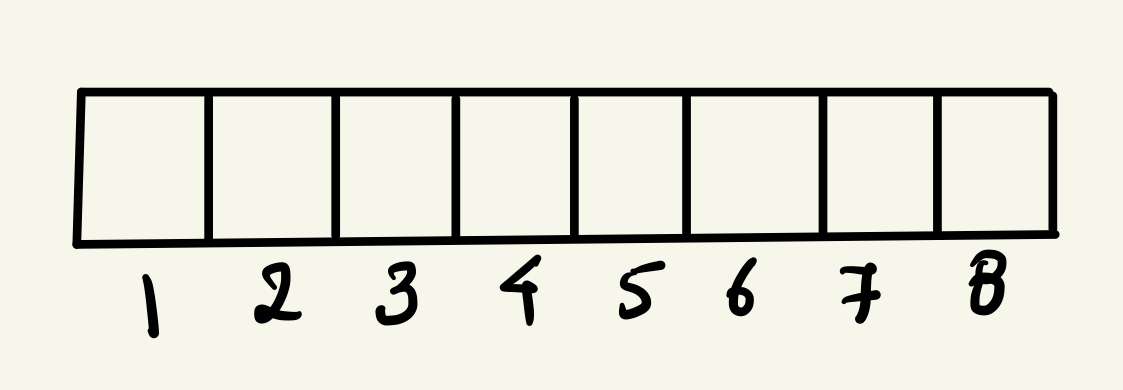
This is an 8-bit bit array. You can read more about it here .
Hash Functions
Hash functions, like any other function, take input and apply some algorithm to change the input to the output called hash value.
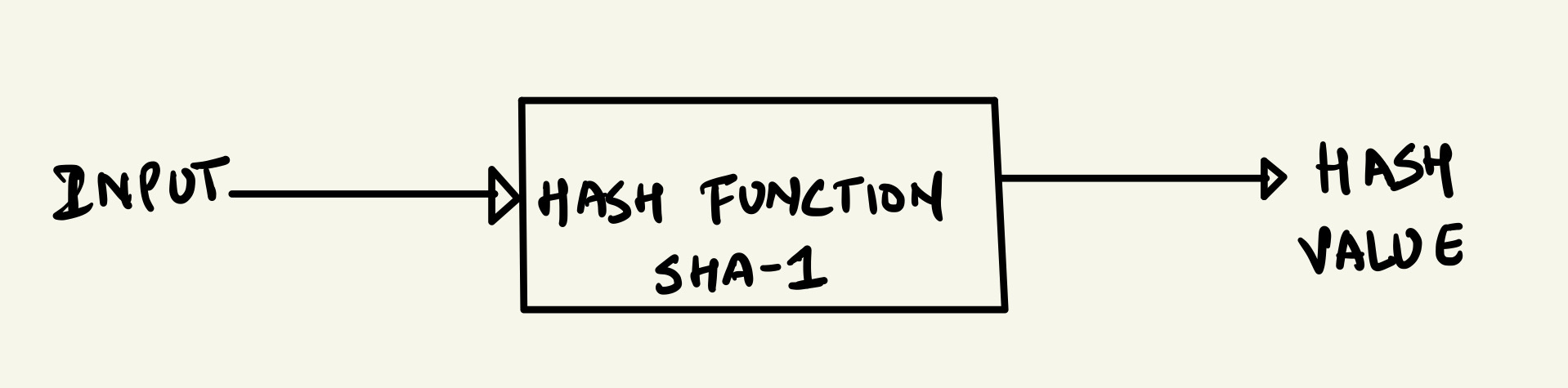
There are various applications of the hash value, one of the most common ones is storing the hash value in a hash table for faster retrieval. One example of the algorithm applied to transform the input is SHA-1.
The properties of hash functions that make them ideal to use it for bloom filters are:
- The length of the output remains the same no matter what is the input.
- Every time you pass the same input, it gives the same output.
You can read more about hash functions here .
How does it work?
To understand how a bloom filter works, let’s take a use case in that we want to store the word “Marvel” in the bit array.
Let’s break down the working of it into steps.
- Initialize the bit array.
- Pass the argument into a group of hash functions.
- Collect the output of each hash function.
- Apply some mathematical logic to obtain bits to update, in our case we are using the modulus operation.
- Update the bits obtained in the previous step with value 1.
Let’s look at the diagram to see the same process in action.
We have initialized the bit array of size 100 with default values as 0.
We pass the argument to a group of hash functions.
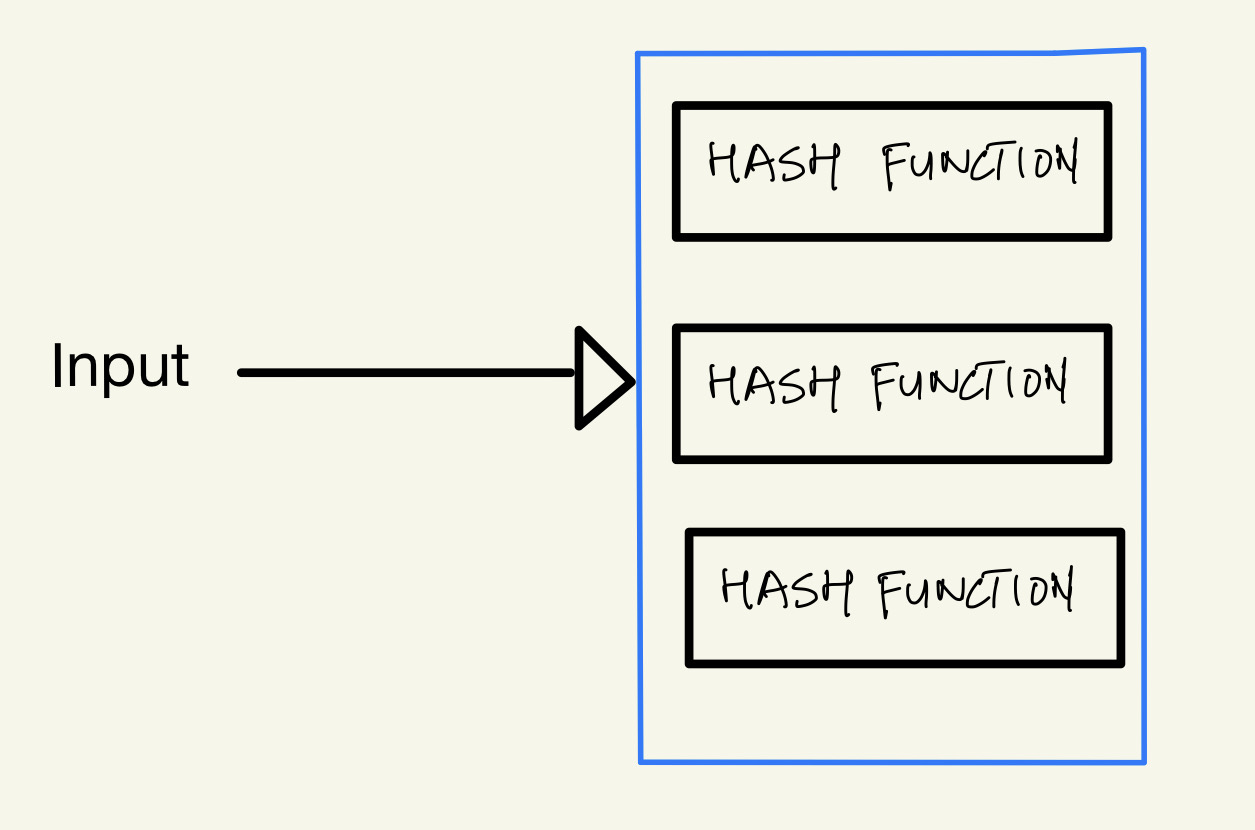
These hash functions give some output.
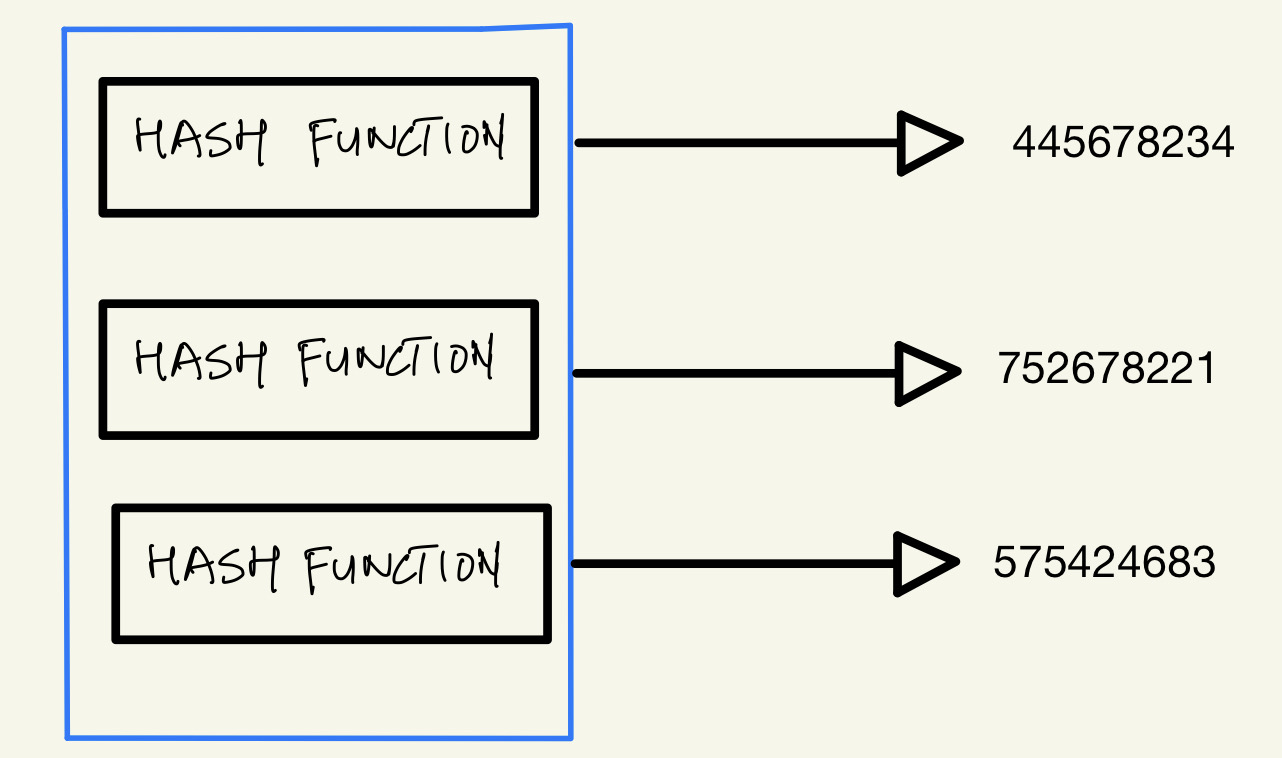
Now we are going to apply the modulus operation to each output of the hash function and we will modulate it by the size of the bit array.
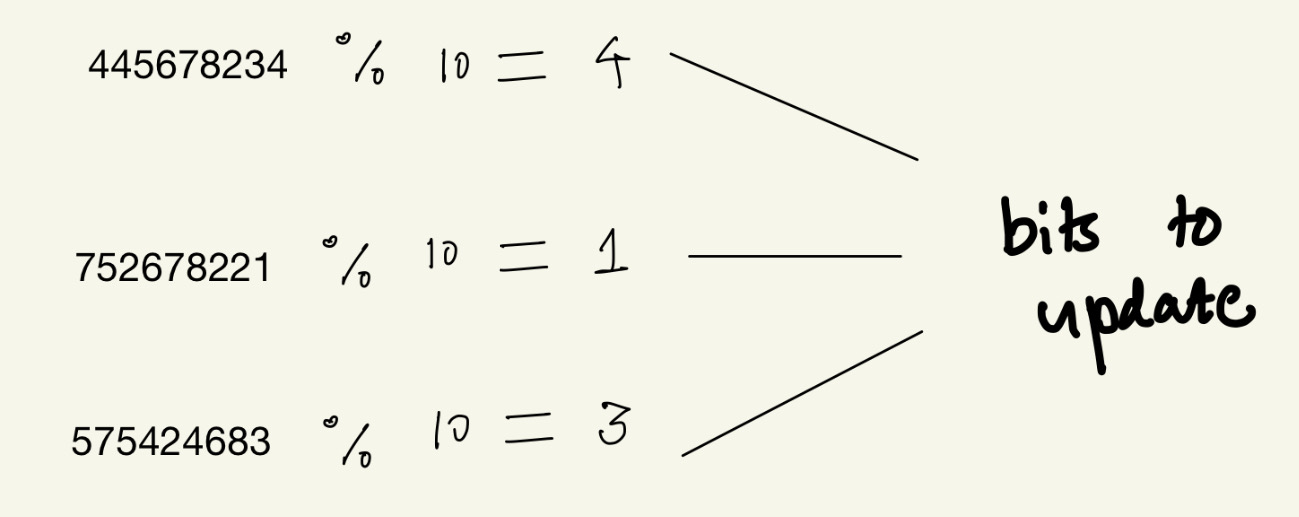
These are the bits that we need to update to store “Marvel” in the bit array.
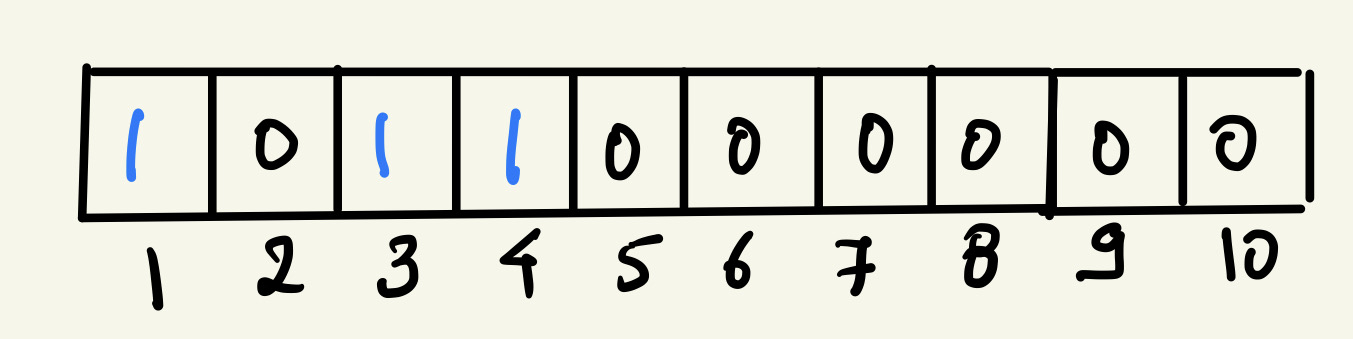
Now if we want to search any word in our bloom filter, we follow the same process except instead of updating the bits with 1, we get the stored value in those bits and if all the values are 1, that means the element is present in the set.
How to implement Bloom Filter?
I am going to implement the bloom filter in ruby.
To implement it, we need to figure out 2 things, one is how to implement a bit array and the second is which hash functions to use.
We are going to use open-source libraries to solve both use cases. The first is https://github.com/peterc/bitarray to initialize and use bit array and the second is an implementation of Murmurhash3 in ruby https://github.com/yoshoku/mmh3/ .
Initializing and using the bit array is as simple as
ba = BitArray.new(20)
ba[4] = 1
read the library’s page for more details.
Similarly, mmh3 gives us options of a few hashing functions. I am going to use this one:
Mmh3.hash128('hello', seed: 5).
Since we would need multiple hash functions, I would change the seed value in the above function to make it behave like 3 different functions.
def hash_function_3(str)
Mmh3.hash128(str, seed: 3)
end
def hash_function_6(str)
Mmh3.hash128(str, seed: 6)
end
def hash_function_8(str)
Mmh3.hash128(str, seed: 8)
end
Now that we know the building blocks of the bloom filter, this is what the implementation of it in ruby looks like.
require 'mmh3'
require 'bitarray'
require 'faker'
class BloomFilter
def initialize(size = 100)
@size = size
@ba = BitArray.new(size)
@names = names
@names.each do |name|
bits = bits_to_update(name)
bits.each { |bit| set_bits_in_array(bit) }
end
end
def fetch_value(pos)
@ba[pos]
end
def bloom_check_present?(str)
puts "Check via include if element is present: #{@names.include?(str)}"
bits = bits_to_update(str)
puts "Check via Bloom filter if element is present: #{bits.collect { |i| @ba[i] }&.compact&.uniq[0] == 1}"
end
private
def names
names = []
100.times { |i| names << Faker::Name.first_name }
names
end
def hash_function_3(str)
Mmh3.hash128(str, seed: 3)
end
def hash_function_6(str)
Mmh3.hash128(str, seed: 6)
end
def hash_function_8(str)
Mmh3.hash128(str, seed: 8)
end
def bits_to_update(str)
bit1 = hash_function_3(str) % @size
bit2 = hash_function_6(str) % @size
bit3 = hash_function_8(str) % @size
[bit1, bit2, bit3]
end
def set_bits_in_array(position)
@ba[position] = 1
end
end
We are using the Faker gem to generate some random names to store in a bit array.
irb(main):018:0> s = BloomFilter.new 1000
=> #<BloomFilter:0x00005555b60c4020 @size=1000, @ba=#<BitArray:0x00005555b60d3f98 @size=1000, @reverse_byte=true>, @names=["Jacques", "Dusti", "Leonel", "Jerrod", "Carroll", "Quiana", "Gianna", "Andrea", "Paulita", "Thao", "Carl", "Angelo", "Milford", "Edyth", "Melinda", "Richie", "Gladis", "Sabra", "Awilda", "Angelica", "Vi", "Tyler", "German", "Annetta", "Micheal", "Gregory", "Rheba", "Marjorie", "Fatimah", "Esteban", "Gil", "Wally", "Max", "Christeen", "Korey", "Josh", "Gaston", "Neil", "Donte", "Rodolfo", "Freddie", "Damon", "Laura", "Malik", "Emerson", "Mariela", "Nilsa", "Larita", "Alexis", "Reynaldo", "Ferdinand", "Ashlee", "Carey", "Martha", "Eladia", "Tammera", "Idalia", "Seymour", "Vaughn", "Bridgett", "Cherryl", "Winnie", "Sade", "Chong", "Phillis", "Denis", "Tad", "Van", "Lenard", "Jody", "Guillermo", "Brady", "Ezekiel", "Abby", "Hilton", "Garry", "Celesta", "Shon", "Candance", "Darin", "Kip", "Elane", "Phillip", "Kiley", "Brittney", "Alexander", "Florine", "Lillia", "Asa", "Akilah", "Blake", "Cherly", "Ezekiel", "Chaya", "Kera", "Lonnie", "Rachal", "Kendall", "Buford", "Garnet"]>
irb(main):024:0> s.all_names
=> ["Jacques", "Dusti", "Leonel", "Jerrod", "Carroll", "Quiana", "Gianna", "Andrea", "Paulita", "Thao", "Carl", "Angelo", "Milford", "Edyth", "Melinda", "Richie", "Gladis", "Sabra", "Awilda", "Angelica", "Vi", "Tyler", "German", "Annetta", "Micheal", "Gregory", "Rheba", "Marjorie", "Fatimah", "Esteban", "Gil", "Wally", "Max", "Christeen", "Korey", "Josh", "Gaston", "Neil", "Donte", "Rodolfo", "Freddie", "Damon", "Laura", "Malik", "Emerson", "Mariela", "Nilsa", "Larita", "Alexis", "Reynaldo", "Ferdinand", "Ashlee", "Carey", "Martha", "Eladia", "Tammera", "Idalia", "Seymour", "Vaughn", "Bridgett", "Cherryl", "Winnie", "Sade", "Chong", "Phillis", "Denis", "Tad", "Van", "Lenard", "Jody", "Guillermo", "Brady", "Ezekiel", "Abby", "Hilton", "Garry", "Celesta", "Shon", "Candance", "Darin", "Kip", "Elane", "Phillip", "Kiley", "Brittney", "Alexander", "Florine", "Lillia", "Asa", "Akilah", "Blake", "Cherly", "Ezekiel", "Chaya", "Kera", "Lonnie", "Rachal", "Kendall", "Buford", "Garnet"]
irb(main):030:0> s.bloom_check_present?('Jay')
Check via include if element is present: false
Check via Bloom filter if element is present: true
irb(main):033:0> s.bloom_check_present?('Buford')
Check via include if element is present: true
Check via Bloom filter if element is present: true
irb(main):037:0> s.bloom_check_present?('Kumar')
Check via include if element is present: false
Check via Bloom filter if element is present: false
We are doing 2 checks, one is via the include? method on the array of names which will give me accurate results and the other one is via the bloom filter to demonstrate the probabilistic nature of the data structure.
Look at the code in line 30, we get 2 different outputs from the 2 different checks. A simple search in arrays gives the element Jay is not present while the bloom filter gives the element is present.
And if you look in line 37 where we search for the element Kumar, both the methods give us that the element does not exist.
Special properties of Bloom Filter
We discussed earlier that the 2 special properties of bloom filters are being space efficient and probabilistic in nature.
Now, we have seen that when we want to store any data, we transform that data into bit positions and then update only those bit positions. This update happens over the same bit array, and that makes it space-efficient as storing boolean values in a single-bit array takes up far less space compared to storing actual text values in the database.
The other special property is that it is probabilistic in nature. So let’s consider this example, we have a bit array of 8 bits and it is storing 2 words right now, “Marvel” and “Wanda”. This is what the representation of these 2 words looks like in a single-bit array:
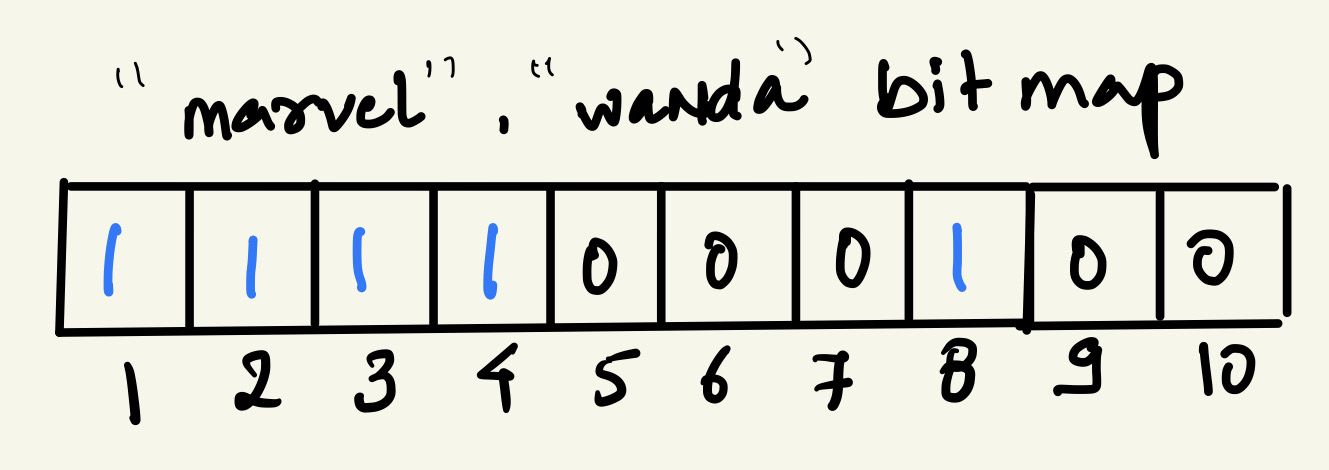
Now, if we were to search for the word “Thanos”, we would have to pass the word through the hash functions and obtain the bits. We would then check if those bits have a value of 1 and, if all the bits have a value of 1, it would mean that the word exists.
So let’s say “Thanos” when passed through hash functions gives bits 2, 4, 8 and, if we look at the bit array, the positions at 2, 4, and 8 have a value of 1. So this would mean that the word does exist in the filter but, in reality, it does not. These bits were set to 1 while storing the words “Marvel” and “Wanda”.
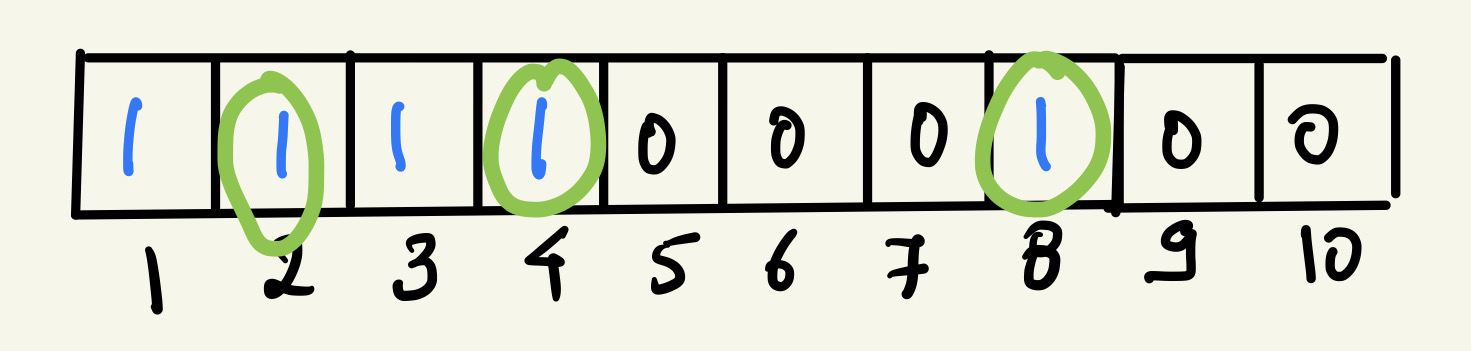
When the output of the bloom filter is positive, i.e the element is found in the set, it may or may not be true. So it could also be a false positive.
But if the output of the bloom filter is negative, i.e the element is not found in the set, it definitely does not exist in the set.
This is what makes the data structure probabilistic in nature.
The caveat with Bloom Filters
While designing any system, we make a choice to use certain components or data structures to solve certain problems. And all these decisions come with some pros and cons. This is true for Bloom Filters as well.
While it does solve a lot of problems for the system, it comes with a condition that you cannot delete elements from the bloom filter.
If we delete an element, it would mean resetting its corresponding bits to 0 but those bits would also be overlapped by some other element’s bits and we would technically be deleting more than 1 element from the set.
On the other hand, Bloom Filter is great at finding if an element is part of the set or not.
Applications of Bloom Filter
-
Check username availability on any platform When the user types in the username of their choice, the platform can check in the bloom filter if the username is already present in the database or not. This is useful when you have a really large data set of usernames in the table and just a simple SQL query will take up a lot of time to give the result.
-
Medium recommendation engine The blogging platform uses bloom filters to not give recommendations to the user of the blogs they have already read.
-
Unsafe Url detection in Chrome Google Chrome uses this to warn users of unsafe websites when they try to visit one.
There are so many other applications of Bloom Filter. I suggest a quick Google search, which will give you ample results.
Benchmarking Results
I created a mysql database with a table called Persons with a varchar column name and inserted 100 million unique records to it.
Using the slightly modified bloom filter script from above, I benchmarked the results when I fired a LIKE query in mysql to search for a name and when I used bloom filter to check the presence of the name. Here are the results.
Benchmarking the mysql query:
Benchmark.bm do |x|
x.report { client.query("select * from Person where name LIKE 'Gov. Saturnina Nicolas'").each { |r| puts r } }
end
user system total real
{"name"=>"Gov. Saturnina Nicolas"}
0.002761 0.000000 0.002761 ( 3.620168)
=> [#<Benchmark::Tms:0x000055cffb6b3930 @label="", @real=3.620167674998811, @cstime=0.0, @cutime=0.0, @stime=0.0, @utime=0.0027609999997366685, @total=0.0027609999997366685>]
This report shows the user CPU time, system CPU time, the sum of the user and system CPU times, and the elapsed real time. The unit of time is seconds. So the real time it took was 3.6 seconds.
Benchmarking the bloom filter check:
s.bm_bloom_check('Gov. Saturnina Nicolas')
user system total real
0.000031 0.000000 0.000031 ( 0.000026)
[#<Benchmark::Tms:0x000055cffb69eaf8 @label="", @real=2.596700142021291e-05, @cstime=0.0, @cutime=0.0, @stime=0.0, @utime=3.099999958067201e-05, @total=3.099999958067201e-05>]
The real time it took was 26/1000000 of a second.
This would give you an idea of how much of a difference a bloom filter can make at scale. I hope this gives you an idea of the bloom filter, it’s workings, and its applications. And if you want to read more about it, here is a great blog post on it.